




题目
题目描述
为了准备一个独特的颁奖典礼,组织者在会场的一片矩形区域(可看做是平面直角坐标系的第一象限)铺上一些矩形地毯。一共有 张地毯,编号从 到 。现在将这些地毯按照编号从小到大的顺序平行于坐标轴先后铺设,后铺的地毯覆盖在前面已经铺好的地毯之上。
地毯铺设完成后,组织者想知道覆盖地面某个点的最上面的那张地毯的编号。注意:在矩形地毯边界和四个顶点上的点也算被地毯覆盖。
输入格式
输入共 行。
第一行,一个整数 ,表示总共有 张地毯。
接下来的 行中,第 行表示编号 的地毯的信息,包含四个整数 ,每两个整数之间用一个空格隔开,分别表示铺设地毯的左下角的坐标 以及地毯在 轴和 轴方向的长度。
第 行包含两个整数 和 ,表示所求的地面的点的坐标 。
输出格式
输出共 行,一个整数,表示所求的地毯的编号;若此处没有被地毯覆盖则输出 -1。
样例 #1
样例输入 #1
3
1 0 2 3
0 2 3 3
2 1 3 3
2 2
样例输出 #1
3
样例 #2
样例输入 #2
3
1 0 2 3
0 2 3 3
2 1 3 3
4 5
样例输出 #2
-1
提示
【样例解释 1】
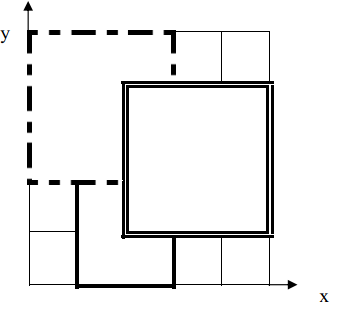
如下图, 号地毯用实线表示, 号地毯用虚线表示, 号用双实线表示,覆盖点 的最上面一张地毯是 号地毯。
【数据范围】
对于 的数据,有 。
对于 的数据,。
对于 的数据,有 , 。
NOIP2011 提高组 day1 第 题。
解题
方法一:模拟 枚举
思路
本题我最开始想到的做法是二维差分,毕竟需要批量操作子矩阵,很自然地就想到了二维差分来做。但是仔细看数据范围发现:地毯左下角坐标和在 轴延伸的长度最大都是 ,也就是说地毯右下角坐标最大可能会到 ,二维数组至少要开到 ,占用 内存空间,显然会 MLE (倒不如说会直接爆栈)。
化繁为简,因为地毯是从底层向高层一层一层给出的,所以其实我们只需要记下每一层地毯的 ,然后找到最上层的一个地毯,使得 即为该点被覆盖的地毯。
代码
倒序遍历:
import java.util.*;
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
in.nextToken(); int n = (int) in.nval;
int[][] carpets = new int[n + 1][4];
for (int i = 1; i <= n; ++i) {
in.nextToken(); carpets[i][0] = (int) in.nval;
in.nextToken(); carpets[i][1] = (int) in.nval;
in.nextToken(); carpets[i][2] = (int) in.nval + carpets[i][0];
in.nextToken(); carpets[i][3] = (int) in.nval + carpets[i][1];
}
in.nextToken(); int x = (int) in.nval;
in.nextToken(); int y = (int) in.nval;
for (int i = n; i >= 1; --i) {
int x1 = carpets[i][0], y1 = carpets[i][1], x2 = carpets[i][2], y2 = carpets[i][3];
if (x >= x1 && x <= x2 && y >= y1 && y <= y2) {
System.out.println(i);
return;
}
}
System.out.println(-1);
}
}
正序遍历:
import java.util.*;
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
in.nextToken(); int n = (int) in.nval;
int[][] carpets = new int[n][4];
for (int i = 0; i < n; ++i) {
in.nextToken(); carpets[i][0] = (int) in.nval;
in.nextToken(); carpets[i][1] = (int) in.nval;
in.nextToken(); carpets[i][2] = (int) in.nval;
in.nextToken(); carpets[i][3] = (int) in.nval;
}
in.nextToken(); int x = (int) in.nval;
in.nextToken(); int y = (int) in.nval;
int ans = -1;
for (int i = 0; i < n; ++i) {
int x1 = carpets[i][0], y1 = carpets[i][1], x2 = x1 + carpets[i][2], y2 = y1 + carpets[i][3];
if (x >= x1 && x <= x2 && y >= y1 && y <= y2) ans = i + 1;
}
System.out.println(ans);
}
}
评论区